本記事では、AWSが提供する公式サンプル「Contact Center GenAI Agent」を紹介します。
日本語で呼ぶなら「コールセンター向け生成AIエージェント」でしょうか。長いので、本記事では以降「CCAIエージェント」と呼びます。
このサンプルは、Amazon Connect を活用したコンタクトセンターに、Amazon Bedrock を組み合わせることで、生成AIによる問い合わせ対応を実現するものです。従来のFAQチャットボットとは異なり、Bedrock Knowledge Base を検索して適切な回答を生成する仕組みを備えているのが特徴です。
今回、このサンプルを実際に構築し、動作を検証しました。
本記事では、以下のポイントを中心に解説します。
- システムアーキテクチャと構築手順
CCAIエージェントの全体構成を解説し、AWS サービスを活用した構築手順を紹介 - ナレッジ検索・回答生成の仕組み
Amazon Bedrock Knowledge Base と LLM を活用した応答の流れを説明 - 会話分析と回答精度評価
QuickSight を用いた問い合わせの分析・可視化、LLM を活用した回答精度評価について紹介 - 実運用における課題と検討ポイント
インテント設計やボイス最適化、パーソナライズ対応の課題について整理
システム構成と機能概要
CCAIエージェントのアーキテクチャを解説し、そこで使用されているAWSサービスの役割と主要機能の概要について説明します。
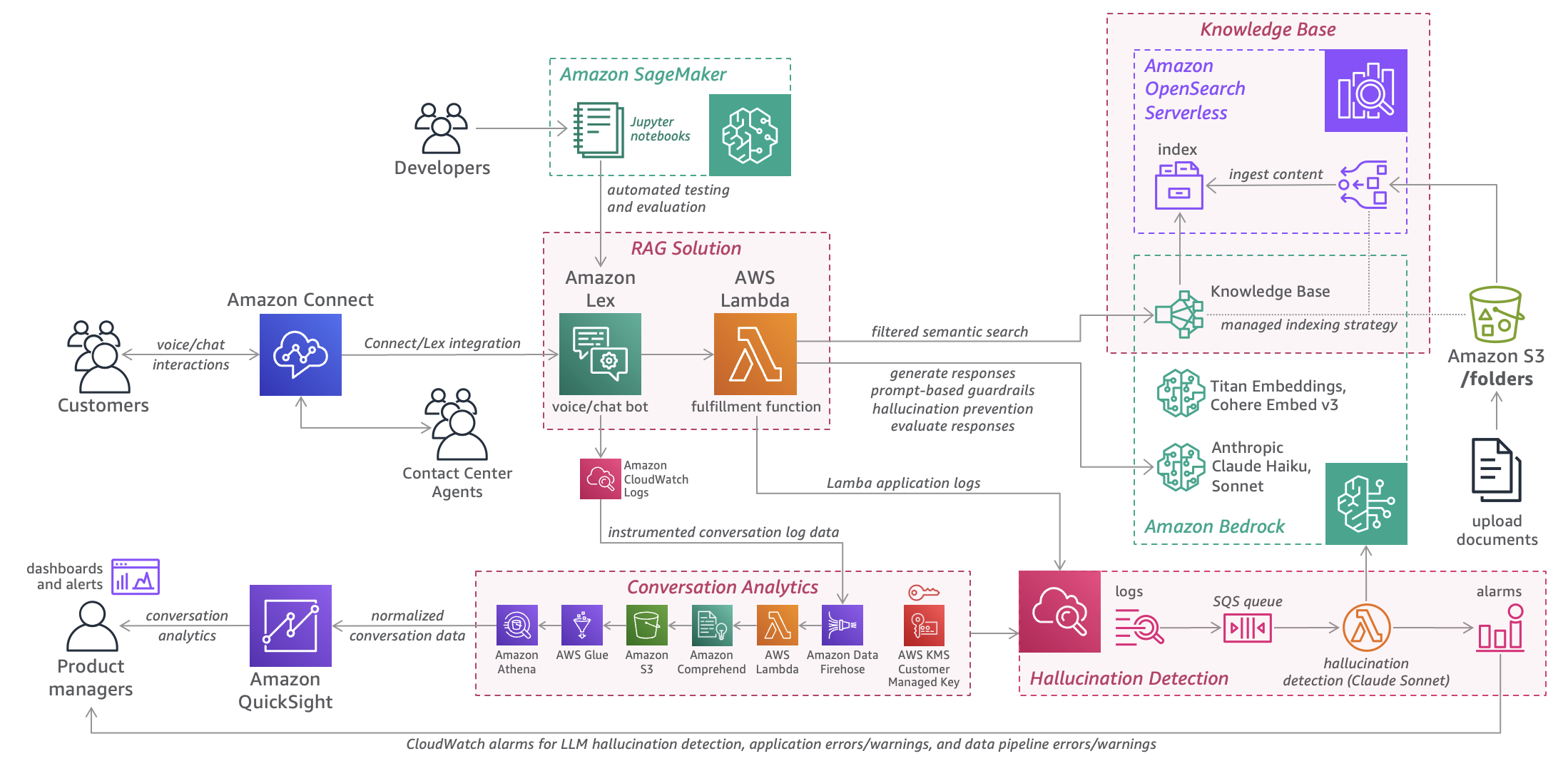
アーキテクチャ
下図は、CCAIエージェントのアーキテクチャ を示しています。本システムでは、Amazon Bedrock Knowledge Base を活用したナレッジ検索や LLM による回答生成を通じて、ユーザーの質問に適切に対応できる仕組みを備えています。
さらに、問い合わせの受付から発話の解析、回答の提供、ログの分析、回答精度の評価までのプロセスを自動化し、業務の効率化と応答品質の向上を実現します。
加えて、会話ログの収集・分析、ハルシネーション検知、回答精度の評価などを組み合わせることで、継続的な改善と安定した応答品質を支援します。
機能概要
本システムでは、ユーザーの問い合わせ対応を効率的に処理するために、複数の AWS サービスが連携して動作します。問い合わせの受け付けから回答の生成・提供、さらにその後のログ分析や精度評価まで、一連の流れが自動化されています。
以下に、各機能の詳細な処理の流れを説明します。
1. 問い合わせの受付
-
Amazon Connect がユーザーからの音声やチャットによる問い合わせを受け付け
-
Amazon Lex が自然言語理解(NLU)を用いて、問い合わせのインテント(意図)を特定
2. 回答の生成
-
Lex で解析された内容をもとに、Lambda が処理を実行
-
Bedrock Knowledge Base を検索し、ナレッジデータを参照
-
大規模言語モデル(LLM)を活用して適切な回答を生成
3. 応答の提供
-
生成された回答は Lambda から Lex に返され、ユーザーに提供
-
チャットの場合はテキスト形式で、音声通話の場合は Amazon Polly による自然な発話で伝達
4. 会話ログの収集・分析
-
Firehose を利用して会話ログをリアルタイムで S3 に保存
-
Glue によってデータをカタログ化し、Athena で SQL クエリを用いた分析を実施
-
QuickSight を活用することで、視覚的に分析結果を把握
5. ハルシネーション検知
-
SQS を利用した非同期処理により、追加の LLM を用いて誤情報の検出
-
生成された回答が Bedrock Knowledge Base の情報と一致しているかを確認
-
誤った内容が含まれている場合はアラートを発生
6. 回答精度の評価
-
SageMaker を使用して、生成された回答の精度を検証
-
正解データと比較し、意図通りの回答が生成されているかを評価
アプリケーションの構築
公式 GitHub サンプル(contact-center-genai-agent)に沿って、デプロイ手順の概要を説明します。
本サンプルには、仮想ホテルチェーンを想定したナレッジデータや会話サンプルがあらかじめ含まれており、テストデータの準備なしで対話エージェントの動作確認がすぐに可能です(ただし英語のみ対応)。
デプロイ手順の概要
本サンプルは、主に CloudFormation により自動的に構築されますが、QuickSight ダッシュボードの作成や SageMaker ノートブックでの評価の実行など、一部はマネジメントコンソール上で手動操作が必要です。
また、LLM や埋め込みモデルの使用にあたってはリージョンごとに対応状況が異なるため、東京リージョンで構築する場合は、AWS公式ドキュメント を確認し、対応しているモデルを選択してください。
なお、今回の検証では、東京リージョンで環境を構築し、LLM としては、回答生成用に Claude V3 Haiku、ハルシネーション検知用に Claude V3.5 Sonnet を使用しています。CloudFormation スタックは用途別に分かれており、Knowledge Base 構築、ハルシネーション検知、RAG ソリューション、会話分析のスタックがそれぞれ存在します。
以下の図はシステム全体の構成を示し、番号(②〜⑦)は本文中の各ステップの番号と対応しており、それぞれで構築・設定・操作を行う対象の構成要素を表しています。
①(CloudFormationのデプロイに必要なファイルをS3にステージング)は準備作業であり、図には含まれていません。
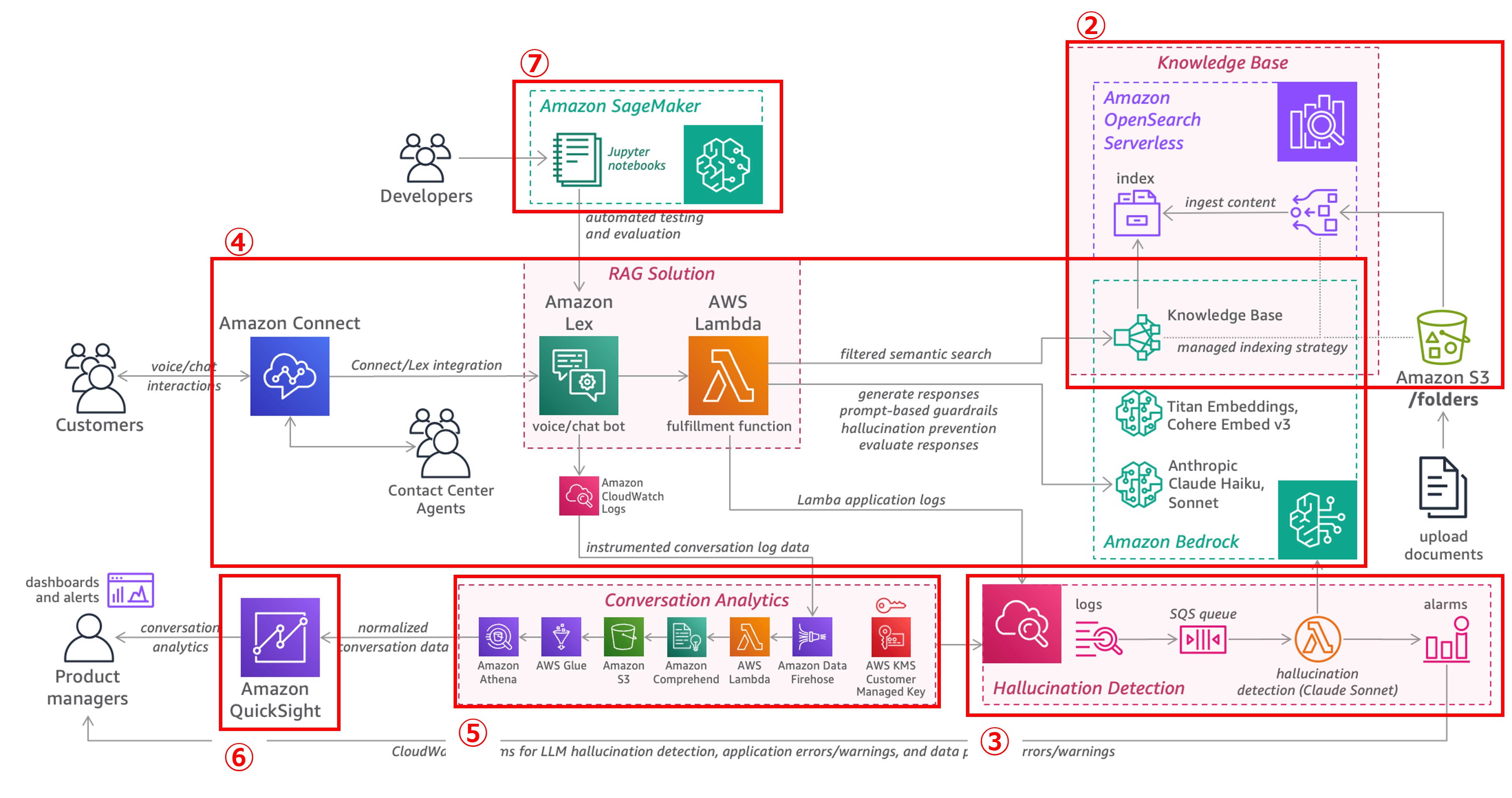
1. CloudFormationのデプロイに必要なファイルをS3にステージング
- CloudFormation のデプロイに必要なテンプレートやスクリプトを S3 に配置
- スタックデプロイ時に S3 上のファイルを参照
2. Knowledge Baseスタックをデプロイ(CloudFormationによる構築)
- ナレッジ検索に必要な Bedrock Knowledge Base や OpenSearch Serverless をセットアップ
- ナレッジデータ(FAQ・マニュアル・社内文書など)を S3 にアップロードし、Knowledge Base との同期処理によりベクトル化を実施
- ベクトル化されたデータをOpenSearch Serverlessにインデックスとして格納
3. Hallucination Detection スタックをデプロイ(CloudFormationによる構築)
- 生成された回答が誤情報を含んでいないかをチェックする機能を追加
- SQS を活用し、非同期でハルシネーション検知を実行
- 回答が Bedrock Knowledge Base の情報と整合性が取れているか検証
4. RAGソリューションスタックをデプロイ(CloudFormationによる構築)
- Lex ボットの設定と Lambda 関数をデプロイ
- 問い合わせに対して Bedrock Knowledge Base の検索結果を用い、LLM による適切な回答を生成
- チャット・音声問わずユーザーの発話内容を Lex に渡すコンタクトフローを Amazon Connect 上に自動で作成
5. 会話分析スタックをデプロイ(CloudFormationによる構築)
- 問い合わせ履歴を蓄積し、分析を行う機能をデプロイ
- Firehose を活用して Lex の会話ログを S3 にストリーミング
- Athenaで分析できるようデータを処理
6. Amazon QuickSightダッシュボードの設定
- 会話ログを視覚的に分析するためのダッシュボードを構築
- 問い合わせの傾向やボットの精度を分析
- 管理者やオペレーターが改善点を把握できる環境を提供
7. 回答精度評価の実行
- SageMakerを用いた回答品質の評価プロセスを実行
- ナレッジと照らし合わせ、生成された回答が適切さを評価
- 評価データをもとにボットの回答精度を改善
アプリケーションの機能紹介
実際に構築したアプリケーションの各機能について、動作の様子や使用する画面とともに紹介します。
自動対話機能
Amazon Connect と Amazon Lex を統合し、音声通話またはチャットでの問い合わせに対する自動応答を実現しています。ユーザーの質問に対し、Lexがインテント(意図)を特定し、ナレッジ検索とRAGによる回答生成を行います。
構築した環境でのチャット画面
以下は、構築した環境でチャットを実行した際の画面です。チャットによる動作確認は、Amazon Connect 管理画面の「チャットをテスト」機能を利用して行います。
本サンプルでは、CloudFormation デプロイ時にテスト用のコンタクトフロー(問い合わせ内容を Lex ボットに連携する処理)が自動で作成されており、追加設定なしで簡単に確認できます。
詳細手順については 公式ドキュメント(Amazon Connect で音声、チャット、タスクのエクスペリエンスをテストする) を参考にしてください。
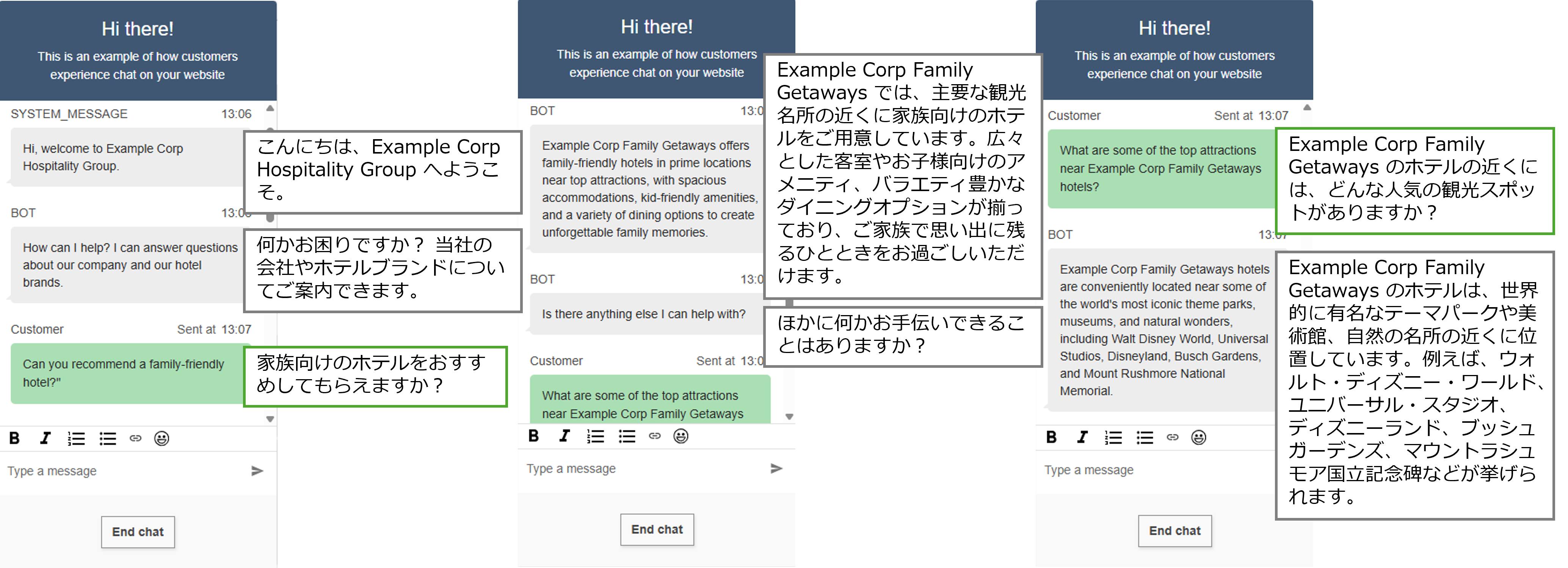
このように、ユーザーからの問い合わせに対し、以下のような一連の処理がバックエンドで実行されています。
- Bedrock Knowledge Base で関連情報を検索し、LLM が回答を生成
- 会話履歴を考慮し、文脈に沿った応答を提供
- ハルシネーション検知による誤情報の通知
- 不適切な発話やプロンプトインジェクション(AIに意図しない動作をさせるような指示)を防ぐガードレールの適用
会話分析
システムで処理された問い合わせ内容や応答の精度を分析・可視化するために、Amazon Athena と Amazon QuickSight を活用しています。この分析により、どのような問い合わせが多いのか、回答精度が適切かなど視覚的に確認でき、継続的なボットのチューニングやナレッジデータの修正、業務改善などに役立ちます。
QuickSight のダッシュボード
以下の図は、検証用に作成した QuickSight ダッシュボードの一例です。左のグラフはインテントごとの問い合わせ数を棒グラフで示し、右のグラフはインテントごとの問い合わせにおけるユーザーの感情の割合を円グラフで示しています。
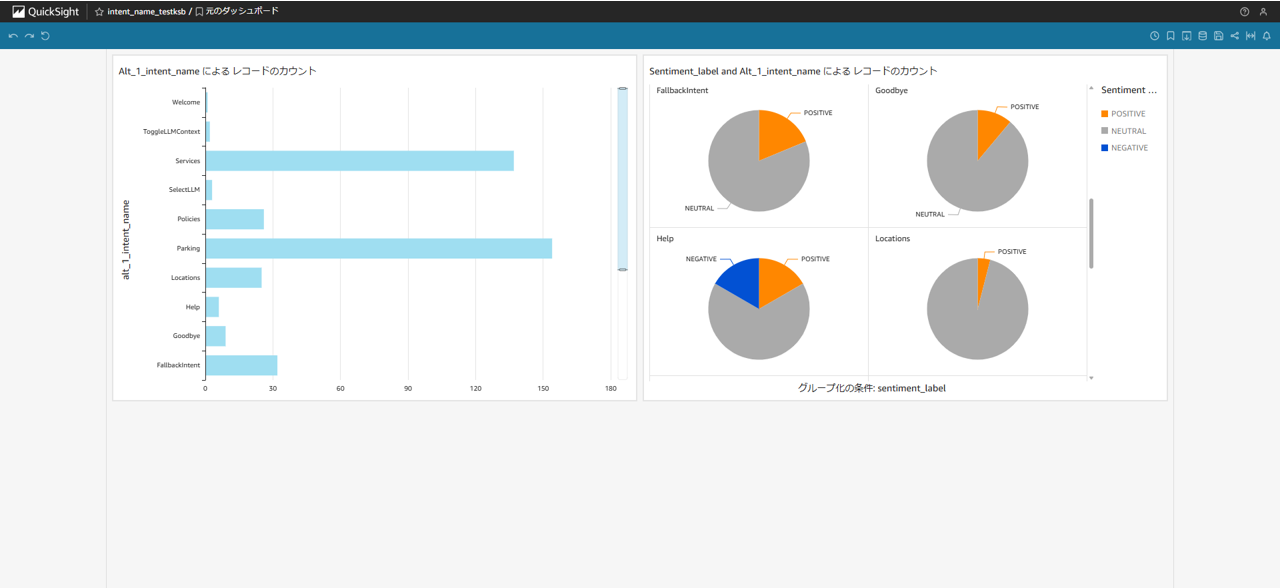
QuickSight では、定期的に更新されるデータを基に、他にも以下のような情報を可視化できます。
- 日付や時間別の問い合わせ件数
- インテント認識の信頼度スコアの分布
- 回答生成やナレッジ検索処理にかかる時間の分析
また、会話ログ分析の際にComprehendによる個人情報(PII)のマスキング機能も存在しますが、現状日本語には対応していません。データは短い間隔で自動更新されるため、最新の問い合わせ状況を把握し、リアルタイムでボットの改善に活用できます。
回答精度評価
本システムでは、Amazon SageMaker を用いて、生成された回答の精度を評価する機能も提供されています。この機能により、期待される回答に近い回答が生成されているか比較評価、Bedrock Knowledge Base に基づいた回答が生成されているかハルシネーション検知を行い、ボットの精度向上を測ります。
回答精度評価の入力と出力項目
評価機能では、以下の項目を含むテストデータを入力し、その処理・分析を通じてモデルの精度を評価できます。
| 項目名 | 説明 |
| 発話内容 | ユーザーが入力した質問 |
| セッション属性 | 使用する Bedrock Knowledge Base や LLM モデルの指定 |
| 期待される回答 | 正解とされる理想的な応答 |
| 期待されるインテント | 質問に対して想定されるインテント |
| 期待される処理状態 | 正常に処理されたかどうかの期待値(例:Fulfilled=すべての必要な情報(スロット)が揃い、回答できる状態 など) |
その結果、以下の表に示す主要な項目を含む出力データが取得できます。
| 項目名 | 説明 |
| 生成された応答 | LLM によって実際に生成された回答 |
| 実際の処理状態 | 正常に処理されたかどうかの状態を表す結果 |
| 実際のインテント | 質問に対してボットが特定したインテント |
| 各種処理時間 | ナレッジ検索や LLM による回答生成、比較評価、ハルシネーション検知にそれぞれ要した時間 |
| 回答の比較評価結果 | 期待される回答と実際に生成された回答とを比較した正誤判定 |
| ハルシネーション検知結果 | 生成された回答に誤情報が含まれていないかの判定 |
これらの出力結果には、以下のような観点での評価や判定結果が含まれており、回答の正確性やナレッジとの整合性を確認し、ボットの改善に役立てることができます。
- 回答の比較評価
- 期待される回答と LLM の生成した回答とを比較し、一致または不一致か判定します。
- 判定理由も出力され、一致の場合には、期待される情報と完全に一致しているか、追加情報が含まれているものの元の意味を変えず補足的な内容にとどまっている場合などが理由として示されます。
- 不一致の場合には、期待される情報の欠落、表現の違いや意味の不一致、追加情報が誤解を生む可能性がある場合などが理由として出力されます。
- ハルシネーション検知
- 生成された回答がナレッジに基づいたものであるかを検証し、誤った情報(ハルシネーション)が含まれていないかを判定します。
- 判定理由も出力され、生成された回答がナレッジデータを正しく参照しているか、ナレッジにない情報が含まれていないかなどが示され、回答のどの部分がドキュメントのどの部分を参照したのかが具体的に記載されます。
- 評価結果をもとにボットを継続的に改善
- 回答の比較評価が不一致である質問やハルシネーションが検知された質問に関して、生成された回答や判定理由などを分析し、プロンプトの最適化やナレッジの補強に活用します。
- 回答の比較評価が不一致である質問やハルシネーションが検知された質問に関して、生成された回答や判定理由などを分析し、プロンプトの最適化やナレッジの補強に活用します。
実運用を想定した場合の課題
本システムを実運用するにあたり、想定される課題のいくつかを以下に示します。
インテントとスロットの選定
ボットの回答精度は、使用する LLM やナレッジデータの質だけでなく、インテントやスロットの設計によっても大きく左右されます。誤ったインテントが選択されると、適切な回答が提供されず、ユーザーの意図とずれた応答が発生する可能性があります。
また、スロットの設定が不十分だと、必要な情報を適切に取得できず、回答の精度が低下する恐れがあります。そのため、コールリーズンを分析し、適切なインテントの分類を行うとともに、スロットの設計を最適化することが重要です。回答精度を高めるには、インテント設計の知見を深め、定期的な評価と継続的な改善に取り組むことが効果的です。
RAGによる応答のボイス最適化
RAG を活用した回答生成は、テキストベースでは適切でも、音声での利用を考慮すると必ずしも最適とは限りません。テキストとしては自然な回答でも、音声で読み上げた際にイントネーションや間の取り方が不自然だと、ユーザーの理解を妨げる可能性があります。また、音声とテキストでは適した表現や構成が異なるため、利用シーンに応じた調整が求められます。
そのため、ボイス最適化のためのプロンプト手法を調査・検証し、自然で分かりやすい応答を生成する仕組みを構築することが重要です。音声応答の品質を向上させるには、最適なプロンプト設計や応答内容の調整を行い、継続的に改善していくことが効果的です。
パーソナライズされた対応
ボットの応答精度を向上させるだけでなく、ユーザーごとに最適な回答を提供するパーソナライズの仕組みも求められます。現在のシステムでは、ナレッジデータをもとに汎用的な回答を生成できますが、個々のユーザーの登録情報や過去の問い合わせ履歴を考慮した応答は不可能な状態です。
例えば、顧客情報のデータベースと連携することで、ユーザーの契約情報や利用履歴に基づいた対応が可能になります。「現在契約しているプランについて知りたい」といった問い合わせに対して、ユーザーごとに異なる適切な案内を提供するといった活用が考えられます。
実運用を想定した場合には、Agent for Bedrock などの機能を活用し、より高度なパーソナライズ対応を実現するための検討が必要となります。
まとめ
本記事ではCCAIエージェントの構築手順や各機能の動作、運用時に想定される課題について解説しました。
RAG を活用した柔軟な回答生成に加え、ハルシネーション検知や回答精度の評価機能により、信頼性の高い対話体験を実現できる構成となっています。現時点では、インテント設計やボイス最適化、パーソナライズ対応など、実運用に向けて検討すべき点も残されていますが、こうした機能を備えた本サンプルは、コンタクトセンターへの生成 AI 活用を検討する際の出発点として有用です。
生成 AI を業務に取り入れる第一歩として、本サンプルを参考にしてみてはいかがでしょうか。
バーチャレクスでは、Amazon Connectの導入支援や、AWS基盤活用のコールセンターシステムクラウドサービス「Connectrek」の開発・提供を行っています。